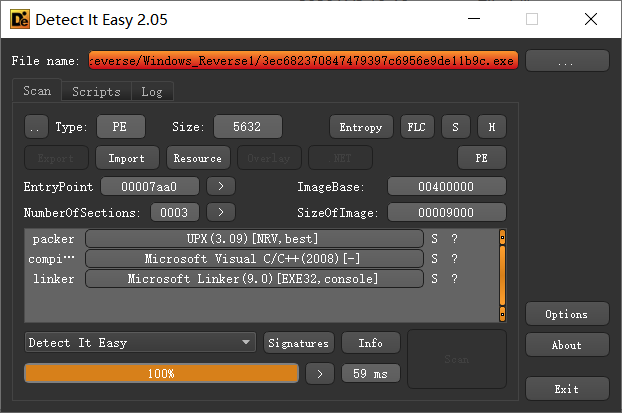
upx的壳,放到kali下 upx -d filename 脱壳即可,使用ida打开
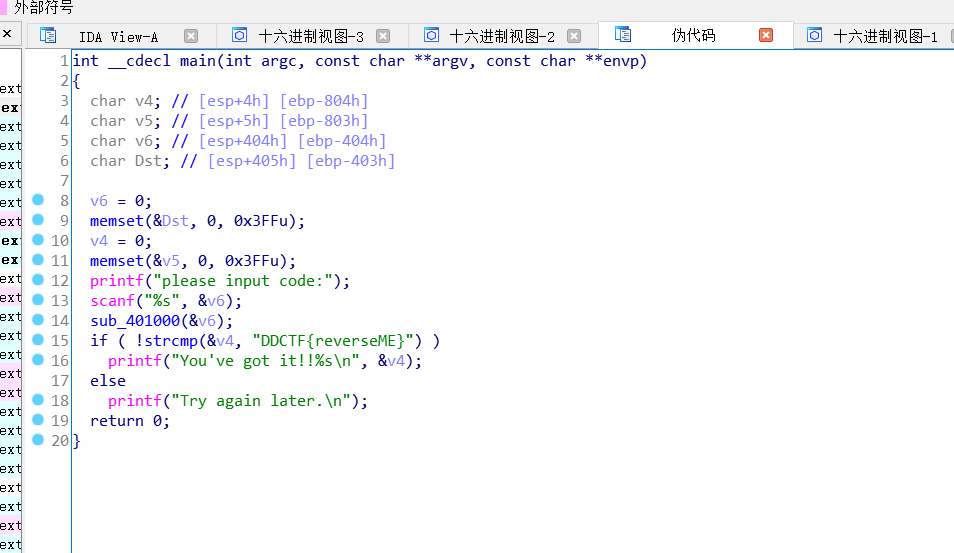
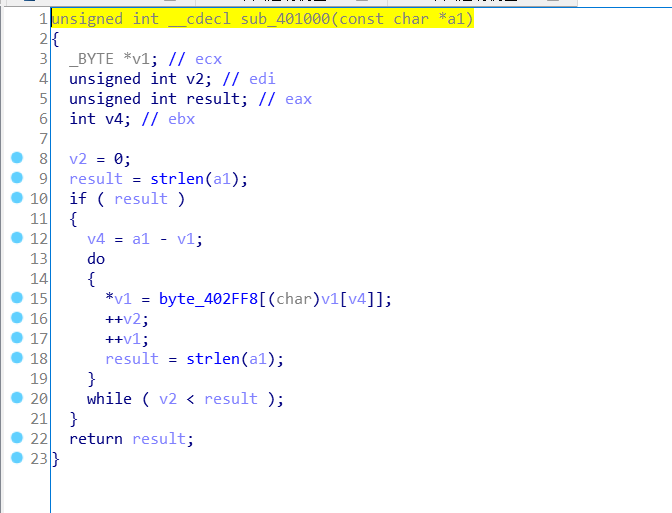
这个函数看着一脸懵,但其实此处的代码逻辑并不复杂:
1.a1是通过压栈的方式传递的参数; v1是通过寄存器保存地址的方式传递的参数
2.最令人迷惑的便是v1[v4]这个地方. v1是一个地址, v4是a1和v1两个地址间的差值. 地址的差值是怎么成为一个数组的索引的呢 ? 这里卡了我好长时间, 之后我突然意识到, v1[v4]和v1+v4是等价的, 而在循环刚开始的时候v1+v4等于a1, 随着v1的递增, v1[v4]也会遍历a1数组中的各个元素的地址
3.而地址又怎么能作为数组的索引呢? 这里就是 IDA 背锅了, 换言之, 做题还是不能太依赖于反编译后的伪代码. 查看了反汇编代码后, 发现其实是将a1字符串中的字符本身作为byte_402FF8的索引, 取值后放入v1数组中
4.查看位于byte_402FF8的值.
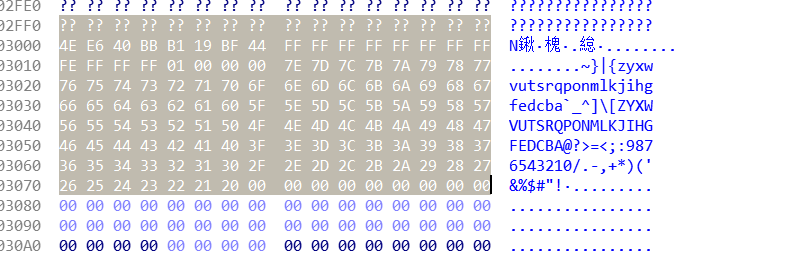
复制下来,写脚本
arr = [0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x4E, 0xE6, 0x40, 0xBB, 0xB1, 0x19, 0xBF, 0x44, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFE, 0xFF, 0xFF, 0xFF, 0x01, 0x00, 0x00, 0x00, 0x7E, 0x7D, 0x7C, 0x7B, 0x7A, 0x79,
0x78, 0x77, 0x76, 0x75, 0x74, 0x73, 0x72, 0x71, 0x70, 0x6F, 0x6E, 0x6D, 0x6C, 0x6B, 0x6A, 0x69, 0x68, 0x67, 0x66,
0x65, 0x64, 0x63, 0x62, 0x61, 0x60, 0x5F, 0x5E, 0x5D, 0x5C, 0x5B, 0x5A, 0x59, 0x58, 0x57, 0x56, 0x55, 0x54, 0x53,
0x52, 0x51, 0x50, 0x4F, 0x4E, 0x4D, 0x4C, 0x4B, 0x4A, 0x49, 0x48, 0x47, 0x46, 0x45, 0x44, 0x43, 0x42, 0x41, 0x40,
0x3F, 0x3E, 0x3D, 0x3C, 0x3B, 0x3A, 0x39, 0x38, 0x37, 0x36, 0x35, 0x34, 0x33, 0x32, 0x31, 0x30, 0x2F, 0x2E, 0x2D,
0x2C, 0x2B, 0x2A, 0x29, 0x28, 0x27, 0x26, 0x25, 0x24, 0x23, 0x22, 0x21, 0x20, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00]
str = 'DDCTF{reverseME}'
flag = ''
for i in str:
flag += chr(arr[ord(i)])
print flag
#ZZ[JX#,9(9,+9QY!