一.概述
最近想收集全市的ICP备案域名信息,想着从工信部的官网上抓包获取查询接口,但是发现有验证码,而且还很复杂,于是想从网上找一些免费的接口,找了半天也没有找到,所有接口都是收费的,价格虽然不高,几分钱查询一次,但是禁不住我查询量大。综合价格和各网站提供接口的方式发现,他们应该都是从工信部官网获取的数据,有一定的难度造成不免费提供,但收费的价格并不高,并且有多家网站可以提供,说明获取数据的难度不是特别大,依我的经验来看,价值几千块的定制化代码的学习成本应该不会超过一个月时间,所以我思考了很多种获取数据的方式,最终确定了技术方案应该是由机器识别验证码来获取数据。
二.实现细节
工信部ICP查询有两种方式:
使用备案号进行查询,验证码较长,6位
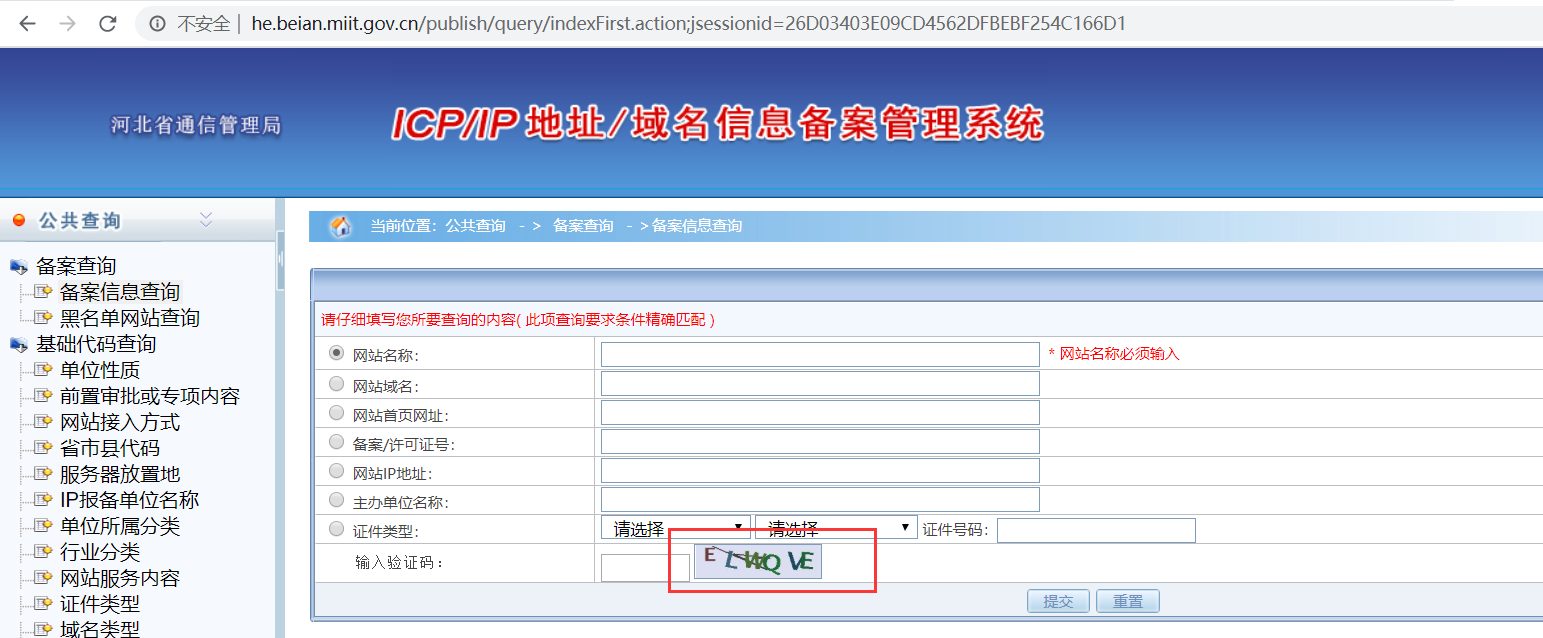
使用数据库自增id查询,验证码较短,4位

使用备案号查出列表后,点击详情的请求为第二种接口
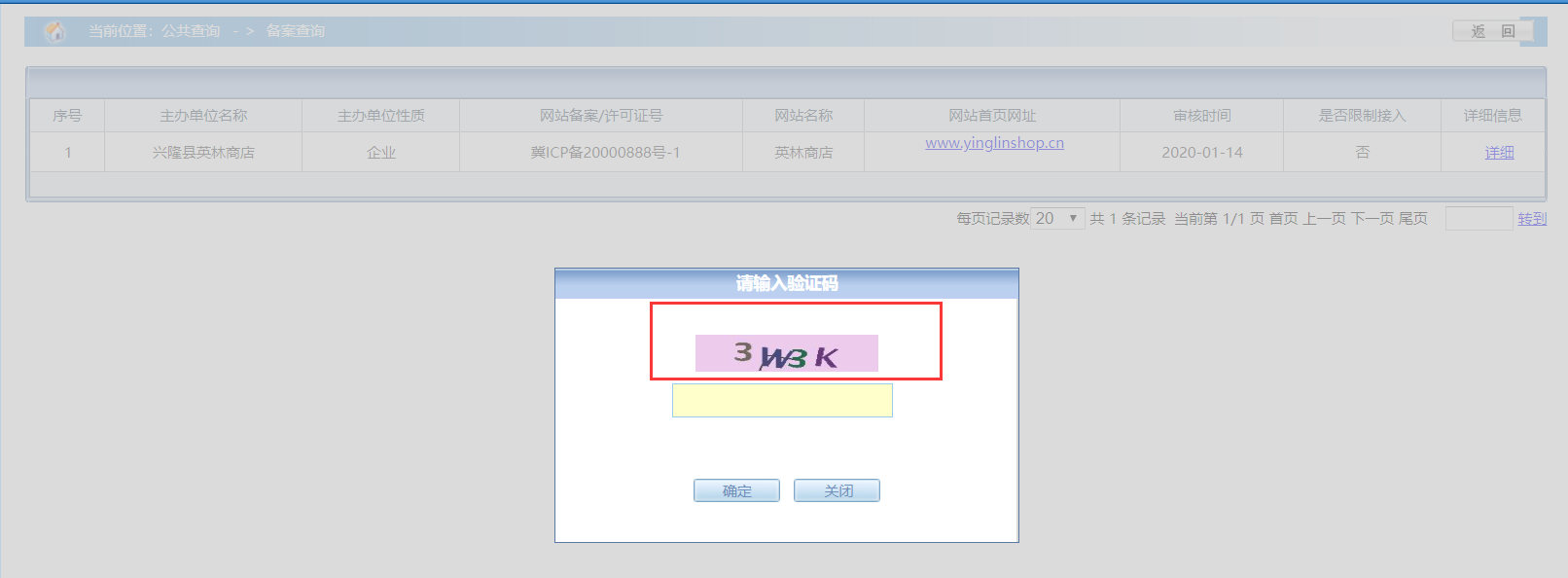
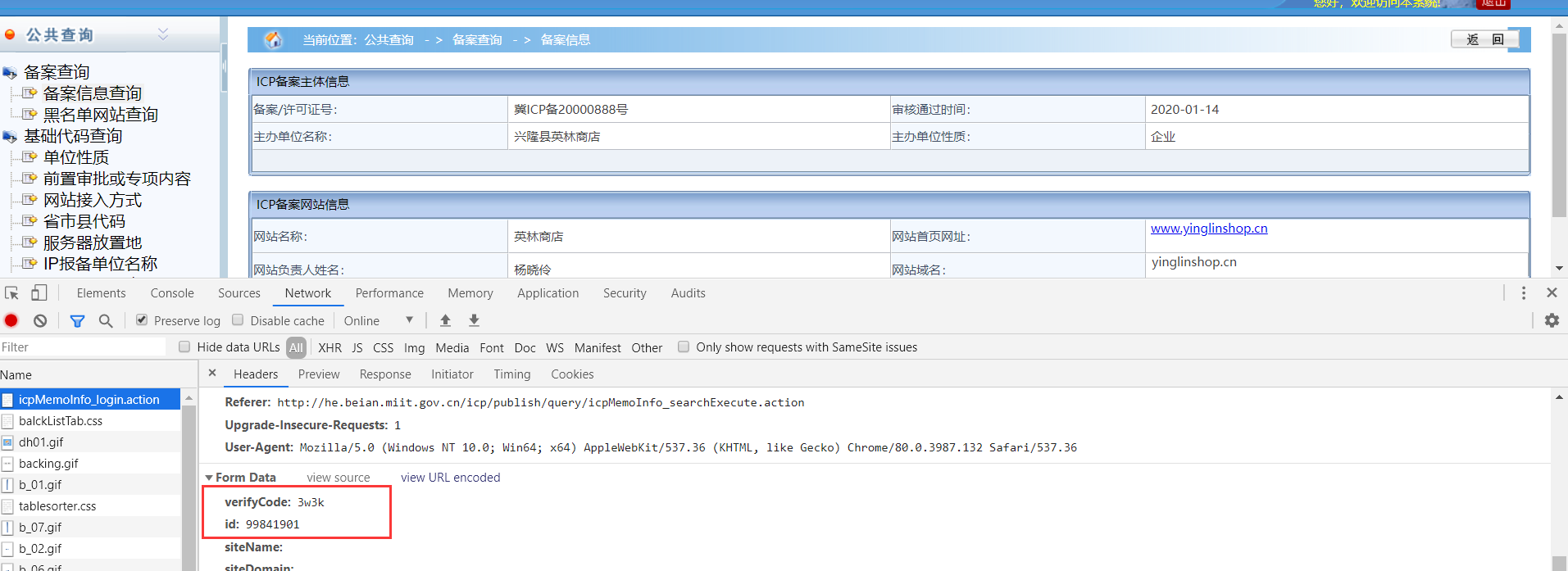
id=99841901,数据库中大概有九千万条数据,只要我们可以自动输入验证码,我们可以把数据全部跑出来,测试了几条大部分id都是空数据。
机器学习识别验证码
接下来我们要使用tensorflow实现卷积神经网络,进行验证码识别。
在github上有很多相关框架,经过多番测试,最后我使用的是cnn_captcha
地址:https://github.com/nickliqian/cnn_captcha
将项目下载到本地后,先安装所有依赖包,使用清华镜像加快下载速度
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
此代码没有标注python的版本,在经历各种报错折磨之后,得出结果运行环境为python3.6,注意不能是3.7,因为3.7没有tensorflow==1.7.0的版本,只有高版本。
然后经过我的几天测试,有独立显卡的使用gpu训练会提升很大的效率。(只有nvidia显卡可以使用gpu训练,用cpu训练的话,不需要安装cuda和cudnn)
安装gpu版本的tensorflow,需要在requirements.txt文件中修改 tensorflow==1.7.0 为 tensorflow-gpu==1.7.0
还需要下载cuda9.0和cudnn7.0,注意版本不要下错,不然无法运行。
cuda9.0下载地址
https://developer.nvidia.com/cuda-toolkit-archive
cudnn7.0下载地址(需要英伟达的账号,懒的注册的可以找我单独给你)
https://developer.nvidia.com/rdp/cudnn-download
安装cuda时候可能由于环境冲突会遇到各种问题,自行百度解决。
安装完成后,就可以进入主题了。
第一步:数据集
我们想要让机器识别验证码,就先需要告诉他什么样是正确的,什么样是错误的,所以需要收集一批正确标注的验证码。

用于训练的验证码图片以 v35g_1583090000.png 格式命名(正确验证码_时间戳.后缀)。
我们要收集第一批用于训练的图片集,第一批数据集收集是最麻烦的,人工识别后给图片修改文件名效率太低,而且太累,我尝试使用免费的文字识别接口,我申请了一个百度的文字识别接口,每天50000次免费,虽然百度识别的正确率只有20%左右,但是对于我们来说足够收集几千张原始数据集了。
我写了一个代码自动下载ICP备案官网的验证码并调用百度接口来识别,识别正确后保存到本地。
# encoding:utf-8
import requests
import base64
import time
import os
# client_id 为官网获取的AK, client_secret 为官网获取的SK
# host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=XXXXXXXX&client_secret=XXXXXXXXXXXXXXXXXXX'
# response = requests.get(host)
# if response:
# # print(response.json())
# access_token = response.json()['access_token']
# print access_token
access_token = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
'''
通用文字识别
'''
def general_basic(filePath):
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"
# 二进制方式打开图片文件
f = open(filePath, 'rb')
img = base64.b64encode(f.read())
params = {"image": img, "language_type": "ENG"}
# access_token = '[调用鉴权接口获取的token]'
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
code = ''
if response:
result = response.json()
print result
for l in result['words_result']:
code += l['words']
final_code = ''
for c in code:
if c != ' ':
final_code += c
if len(final_code) != 4:
return ''
return final_code
headers = {
"Host": "he.beian.miit.gov.cn",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
"Accept": "image/webp,image/apng,image/*,*/*;q=0.8",
"Referer": "http://he.beian.miit.gov.cn/icp/publish/query/icpMemoInfo_searchExecute.action",
"Accept-Language": "zh-CN,zh;q=0.9,und;q=0.8"
}
cookie = ''
k = 0
for i in range(100000):
url = "http://he.beian.miit.gov.cn/getDetailVerifyCode"
r = requests.get(url + '?' + str(i + 1), headers=headers, cookies=cookie)
if cookie == '':
cookie = requests.utils.dict_from_cookiejar(r.cookies)
filePath = 'D:/tmp/' + str(i) + '.png'
with open(filePath, 'wb') as f:
f.write(r.content)
type = 1
# 百度识别
final_code = general_basic(filePath)
if "<" in final_code or ">" in final_code:
continue
if final_code == '':
continue
# print final_code
valid_url = "http://he.beian.miit.gov.cn/icp/publish/query/icpMemoInfo_login.action"
valid_data = {
"verifyCode": final_code,
"id": "96136711",
"siteName": "",
"siteDomain": "",
"siteUrl": "",
"mainLicense": "",
"siteIp": "",
"unitName": "",
"mainUnitNature": "-1",
"certType": "-1",
"mainUnitCertNo": "",
"bindFlag": "0"
}
r2 = requests.post(valid_url, data=valid_data, headers=headers, cookies=cookie)
if u"王敏" not in r2.text:
try:
os.remove(filePath)
except:
print u'出错了'
continue
else:
dstDir = "C:/icp/sample/new_train/" + final_code.lower() + "_" + str(int(time.time())) + ".png"
try:
os.rename(filePath, dstDir)
except:
print u'出错了'
k += 1
print k
# time.sleep(1)运行一段时间之后,我们就保存了几千张正确的验证码,第一批训练数据集收集完成。
第二步:配置文件
配置文件使用如下配置,并创建出相关目录,注意 model_save_dir 是我们训练完成后模型存放的位置,相当于最终训练成果存放位置,指定的是文件名,不是目录
{
"origin_image_dir": "sample/origin/",
"new_image_dir": "sample/new_train/",
"train_image_dir": "sample/train/",
"test_image_dir": "sample/test/",
"api_image_dir": "sample/api/",
"online_image_dir": "sample/online/",
"local_image_dir": "sample/local/",
"model_save_dir": "C:/icp/model/1",
"image_width": 200,
"image_height": 60,
"max_captcha": 4,
"image_suffix": "png",
"char_set": "0123456789abcdefghijklmnopqrstuvwxyz",
"use_labels_json_file": false,
"remote_url": "http://127.0.0.1:6100/captcha/",
"cycle_stop": 20000,
"acc_stop": 0.99,
"cycle_save": 500,
"enable_gpu": 1,
"train_batch_size": 512,
"test_batch_size": 100
}第三步:验证和拆分数据集
首先需要创建和指定三个文件夹:origin,train,test,然后把第一步收集的数据集放到 ./sample/origin 目录下
使用命令校验原始图片集的尺寸和测试图片是否正常,并按照19:1的比例拆分出训练集和测试集
python3 verify_and_split_data.py
会有以下提示
>>> 开始校验目录:[sample/origin/] 开始校验原始图片集 原始集共有图片: 1001张 ====以下1张图片有异常==== [第0张图片] [.DStore] [文件后缀不正确] ========end 开始分离原始图片集为:测试集(5%)和训练集(95%) 共分配1000张图片到训练集和测试集,其中1张为异常留在原始目录 测试集数量为:50 训练集数量为:950 >>> 开始校验目录:[sample/new_train/] 【警告】找不到目录sample/new_train/,即将创建 开始校验原始图片集 原始集共有图片: 0张 ====以下0张图片有异常==== 未发现异常(共 0 张图片) ========end 开始分离原始图片集为:测试集(5%)和训练集(95%) 共分配0张图片到训练集和测试集,其中0张为异常留在原始目录 测试集数量为:0 训练集数量为:0
此外,当你有新的样本需要一起训练,可以放在sample/new_train目录下,再次运行python3 verify_and_split_data.py即可。
需要注意的是,如果新的样本中有新增的标签,你需要把新的标签增加到char_set配置中或者labels.json文件中。
第四步:开始训练
创建好训练集和测试集之后,就可以开始训练模型了。训练的过程中会输出日志,日志展示当前的训练轮数、准确率和loss。此时的准确率是训练集图片的准确率,代表训练集的图片识别情况
例如:
第10次训练 >>>
[训练集] 字符准确率为 0.03000 图片准确率为 0.00000 >>> loss 0.1698757857
[验证集] 字符准确率为 0.04000 图片准确率为 0.00000 >>> loss 0.1698757857
字符准确率和图片准确率的解释:
假设:有100张图片,每张图片四个字符,共400个字符。我们这里把任务拆分为为需要识别400个字符
字符准确率:识别400的字符中,正确字符的占比。
图片准确率:100张图片中,4个字符完全识别准确的图片占比。
这里不具体介绍tensorflow安装相关问题,直奔主题。
确保图片相关参数和目录设置正确后,执行以下命令开始训练:
python3 train_model.py
由于训练集中常常不包含所有的样本特征,所以会出现训练集准确率是100%而测试集准确率不足100%的情况,此时提升准确率的一个解决方案是增加正确标记后的负样本。
训练结束条件在配置文件中可以设置。
第五步:开启api接口
在我们第一次训练完成后,验证码已经有了一定的识别率,几千张的训练成果应该和百度的识别率差不多,我们可以自己开放api接口供别人调用了。
python3 webserver_recognize_api.py
开启api服务后,使用下面代码调用
url = "http://127.0.0.1:6000/b"
files = {'image_file': (image_file_name, open('captcha.jpg', 'rb'), 'application')}
r = requests.post(url=url, files=files)返回的结果是一个json:
{
'time': '1542017705.9152594',
'value': 'g1as',
}成功到达这步之后,我们已经可自给自足了,不需要再使用百度的接口了,使用我们自己开启的接口进行验证码识别,收集第二批、第三批数据集...。
使用本地接口收集数据集代码如下
# encoding:utf-8
import requests
import base64
import time
import os
def local_code(filePath):
request_url = "http://127.0.0.1:6000/b"
files = {'image_file': open(filePath, 'rb')}
response = requests.post(request_url, files=files, headers=headers)
code = ''
if response:
result = response.json()
code = result['value']
return code
headers = {
"Host": "he.beian.miit.gov.cn",
"User-Agent": "Mozilla/6.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
"Accept": "image/webp,image/apng,image/*,*/*;q=0.8",
"Referer": "http://he.beian.miit.gov.cn/icp/publish/query/icpMemoInfo_searchExecute.action",
"Accept-Language": "zh-CN,zh;q=0.9,und;q=0.8"
}
cookie = ''
k = 0
for i in range(100):
url = "http://he.beian.miit.gov.cn/getDetailVerifyCode"
r = requests.get(url + '?' + str(i + 1), headers=headers, cookies=cookie)
if cookie == '':
cookie = requests.utils.dict_from_cookiejar(r.cookies)
filePath = 'D:/tmp/' + str(i) + '.png'
with open(filePath, 'wb') as f:
f.write(r.content)
final_code = local_code(filePath)
valid_url = "http://he.beian.miit.gov.cn/icp/publish/query/icpMemoInfo_login.action"
valid_data = {
"verifyCode": final_code,
"id": "96136711",
"siteName": "",
"siteDomain": "",
"siteUrl": "",
"mainLicense": "",
"siteIp": "",
"unitName": "",
"mainUnitNature": "-1",
"certType": "-1",
"mainUnitCertNo": "",
"bindFlag": "0"
}
r2 = requests.post(valid_url, data=valid_data, headers=headers, cookies=cookie)
if u"王敏" not in r2.text:
os.remove(filePath)
print True
else:
dstDir = "D:/tmp/r/" + final_code.lower() + "_" + str(int(time.time())) + ".png"
os.rename(filePath, dstDir)
# print r2.text
print False第六步:提升识别率
经过我的测试,icp备案查询系统的验证码第一次训练时识别率20%左右,第二次30%左右,随着验证码图片的数量越来越多,识别率会越来越高。提高识别率的方法有很多,作为初学者,我用的最笨也最简单的方法,在不调整参数的情况下,收集足够多的训练样本,用来提升识别率,目前我已收集20万张验证码图片,在线识别率已经到了95%左右,本地识别率99%。如果你有更好的方法,可以联系我一起交流学习。
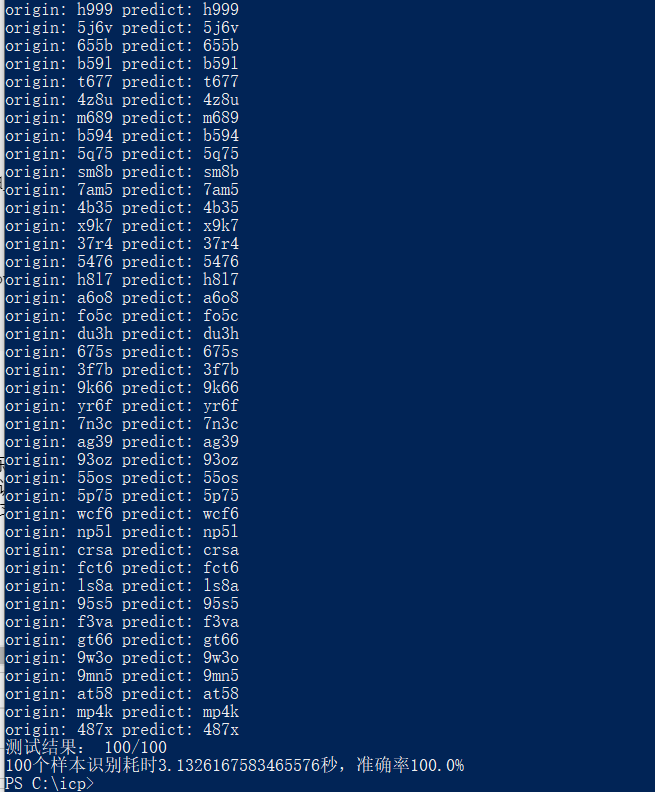
第七步:爬取ICP备案数据
验证码识别率已经达到了95%,可能比我手动输入的正确率都要高,爬取数据已经没有任何问题,全国的ICP备案域名数据量巨大,慢慢跑吧,代码就不放出来了。
三.总结
本次人工智能的学习只是我无意中接触到的,虽然学习过程让我痛苦无比(安装各种环境报错、系统损坏重装一次,丢失很多重要资料、测试识别率的提升方法、人肉标注验证码),耗费一周多的时间,但它的神奇令我印象深刻,之前渗透测试中我对验证码的方式就是手工测试几条弱口令就得了,这次经历让我大开眼界,真的是科技改变生活,学习才能得到真知。